
机器学习慢慢的在各种领域发挥作用,在安全领域也不例外,之前就有类似关于机器学习Web安全的讨论。并且许多甲方公司也在开始研究机器学习对自己安全方向的领域(Web、DDoS)能够发挥什么作用,拭目以待吧:) 。
0x01 kNN
K-NN是一种基于实例的学习,或者是局部近似和将所有计算推迟到分类之后的惰性学习。k-近邻算法是所有的机器学习算法中最简单的之一。
这句话是维基百科里的解释,可以用网上的一幅图来更好的解释这个算法。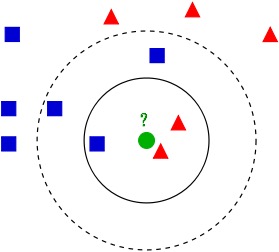
如图有两种类型的数据集,一种是红色三角,另一种为蓝色正方形,假如我要判断绿色是属于哪一类应该如何做?
knn的套路是这样的:
1 首先我们事先定下k值(就是指k近邻方法的k的大小,代表对于一个待分类的数据点,我们要寻找几个它的邻居)。为了说明问题,我们取两个k值,分别为3和5;
2 根据事先确定的距离度量公式(如:欧氏距离),得出待分类数据点和所有已知类别的样本点中,距离最近的k个样本。
3 统计这k个样本点中,各个类别的数量。如图,如果我们选定k值为3,则三角形有2个,方形有1个,那么我们就把这个圆形数据点判断为三角;而如果我们选择k值为5,则三角形有2个,方形有3个,那么我们这个数据点定为方形。
即,根据k个样本中,数量最多的样本是什么类别,我们就把这个数据点定为什么类别。
优缺点:
(1)优点:
算法简单,易于实现,不需要参数估计,不需要事先训练。
(2)缺点:
属于懒惰算法,“平时不好好学习,考试时才临阵磨枪”,意思是kNN不用事先训练,而是在输入待分类样本时才开始运行,这一特点导致kNN计算量特别大,而且训练样本必须存储在本地,内存开销也特别大。
K的取值:
参数k的取值一般通常不大于20。——《机器学习实战》
0x02 数据预处理
我们可以直接用python的scikit-learn库来直接调用,以下是利用iris(鸢尾花)的数据集来作为例子。
iris数据集是由三种鸢尾花,各50组数据构成的数据集。
每个样本包含4个特征,分别为萼片(sepals)的长和宽、花瓣(petals)的长和宽。
所以我要依靠这些特征来判断花的类型。
python的sklearn库里也有存放该数据集,
当然也可以直接载入数据集,利用pandas库.read_csv 直接载入。
由于源数据没有定义字段,所以自己自定义了5个字段
sepal length:萼片(sepals)的长,单位为cm
sepal width:萼片(sepals)的宽,单位为cm
petal length:花瓣(petals)的长,单位为cm
petal width:花瓣(petals)的宽,单位为cm
type:三种鸢尾花的类型(’setosa’ ‘versicolor’ ‘virginica’)
首先看下数据的情况: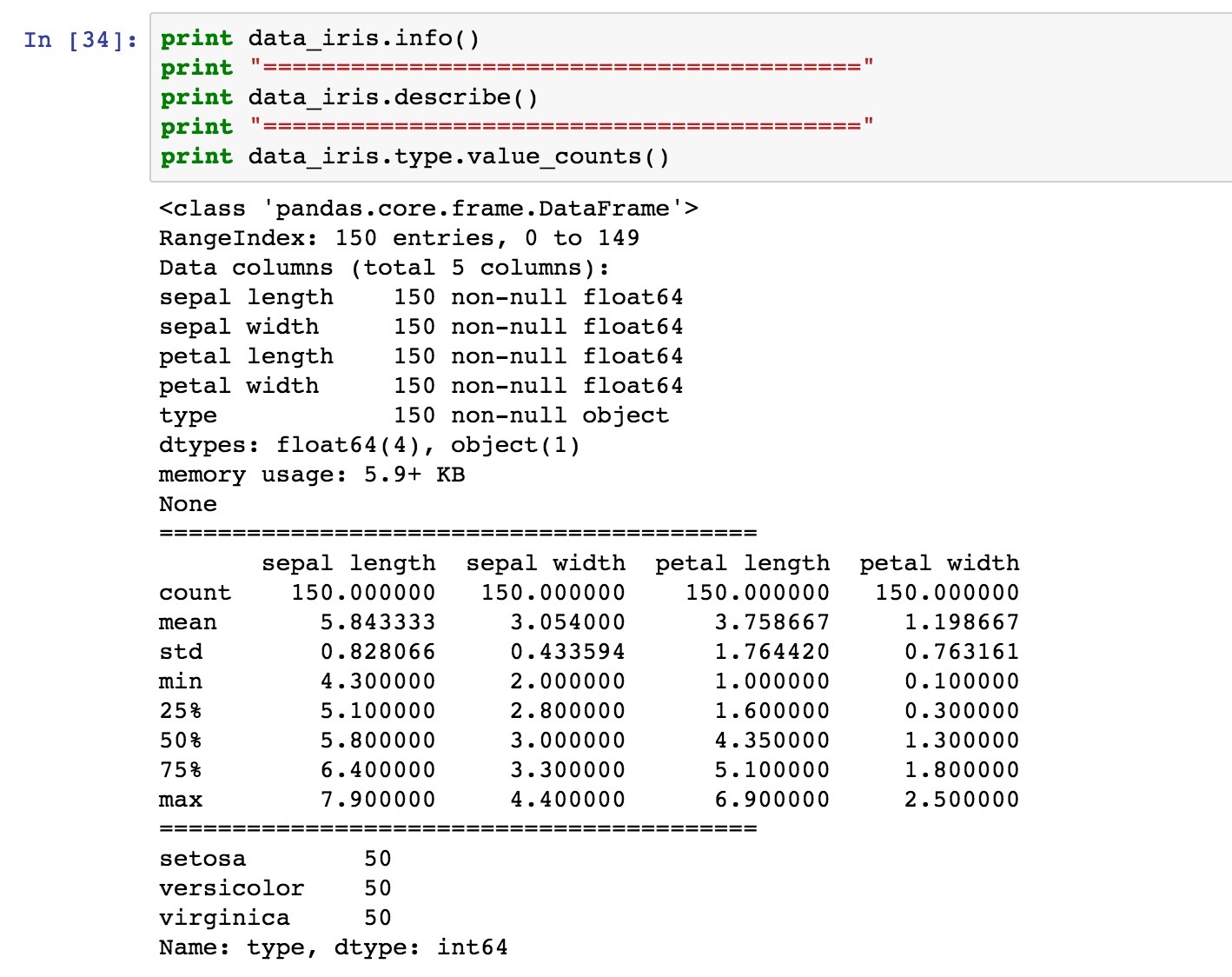
可以看到有150条数据,每个数据的数据类型、一些均值、最大最小值, 三种花各50条数据
我们来做数据的预处理,比如把type属性改成我们计算机熟悉的数字
随意写个函数,把setosa设为0、versicolor为1、virginica为2
0x03 特征工程
当然也可以用图来看看

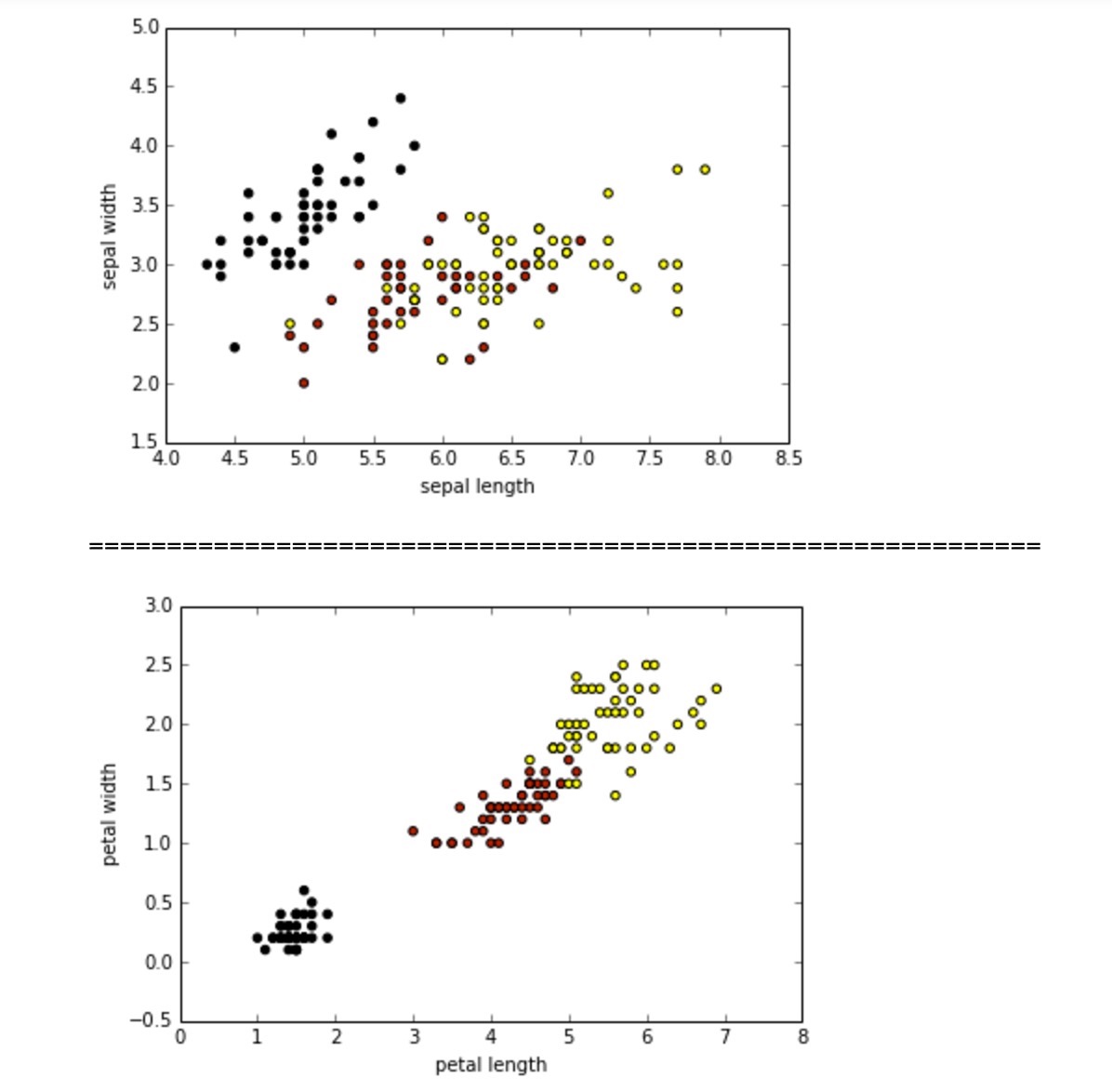
不同颜色表示不同的花,可以发现萼片的长宽与花的类型点比较混杂,而从花瓣的图可以看出来随着长宽的变大,花的类型大概能够分类。
0x04 测试模型
数据处理和特征工程基本完成,开始利用kNN算法进行预测。
这里利用到了交叉验证,k=5 预测的概率达到了0.966左右
我们也可以遍历下k,之后用图来看看k不同对概率的影响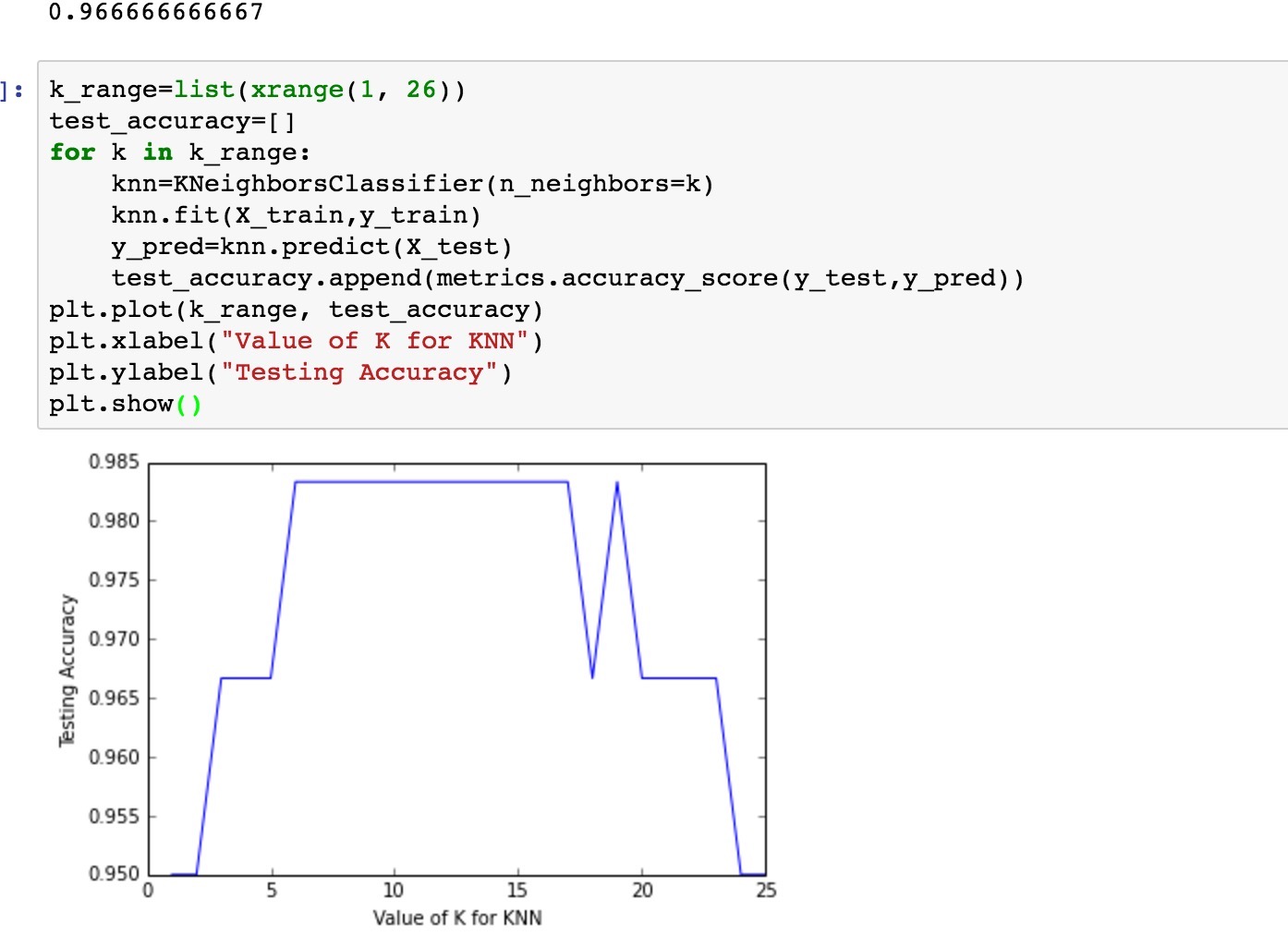
可以发现,k的取值最大最小都会使的概率变得低。